Après avoir vu comment intégrer l’opérateur Nutanix NDB Operator dans le précédent article nous allons ici voir comment il est simple de consommer rapidement des ressources NDB depuis un déploiement.
Avec l’opérateur NDB je vais pouvoir consommer des ressources de la manière suivante :
- Provisionner un serveur de base de données en utilisant les Profiles habituels sur NDB (Compute, Software, Network, DataBase Parameters)
- Cloner une instance de base de données avec les mêmes arguments en indiquant un snapshots de référence pour le clone
- Désenregistrer une base de données et supprimer la VM associée
Récupération des variables
Pour pouvoir correctement appeler les différentes entités (cluster, NDB Server), j’ai besoin de récupérer/déclarer plusieurs variables.
L’IP de mon serveur NDB :
NDB_IP=XXX.XXX.XXX.XXX
L’UUID de mon serveur NDB :
NDB_UUID="$(curl -X GET -u admin -k https://$NDB_IP/era/v0.9/clusters | jq '.[0].id')" echo $NDB_UUID

Construction du manifest
Avec ces valeurs, je peux ensuite construire mon manifest dans la manière suivante :
apiVersion: ndb.nutanix.com/v1alpha1 kind: Database metadata: name: dbnkp namespace: ndb spec: ndbRef: ndb isClone: false databaseInstance: clusterId: $NDB_UUID name: "instanceName" databaseNames: - myDBname credentialSecret: myDBsecret size: 10 timezone: "UTC" type: postgres
Ici, ce manifeste va créer une database sur un serveur postgres en prenant les paramètres par défaut pour les profiles OOB.
(A noter que pour SQL Server et Oracle, les profiles Software sont mandatory, les déploiements nécessitant au préalable l’ajout d’une Golden Image transformée en Sotfware Profile)
J’applique donc mon manifest :
kubectl apply -f database-pg.yaml
Je vérifie la soumission des opérations dans NDB, et une tâche est bien créée :
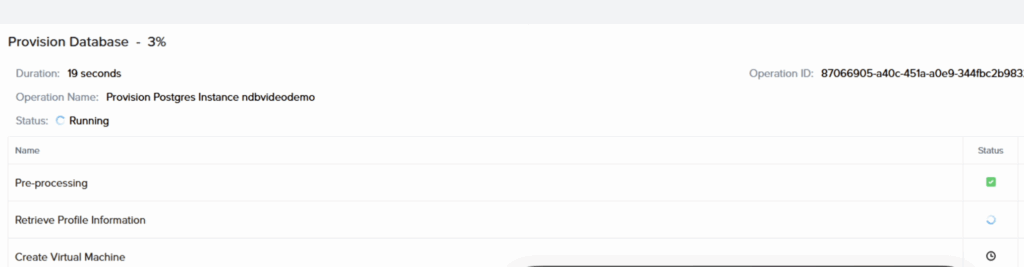
Vérification
Une fois l’ensemble des tâches terminées, je vais pouvoir vérifier l’existance de ma base de données et dans NDB et depuis Kubernetes.
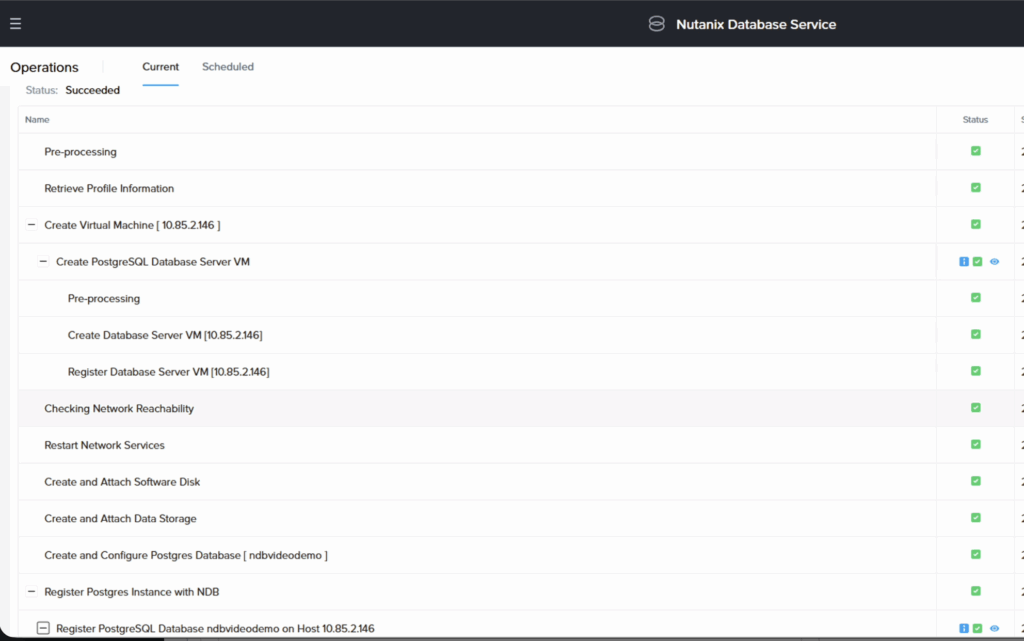
Le serveur est bien visible dans ma liste des DB Server sur NDB :
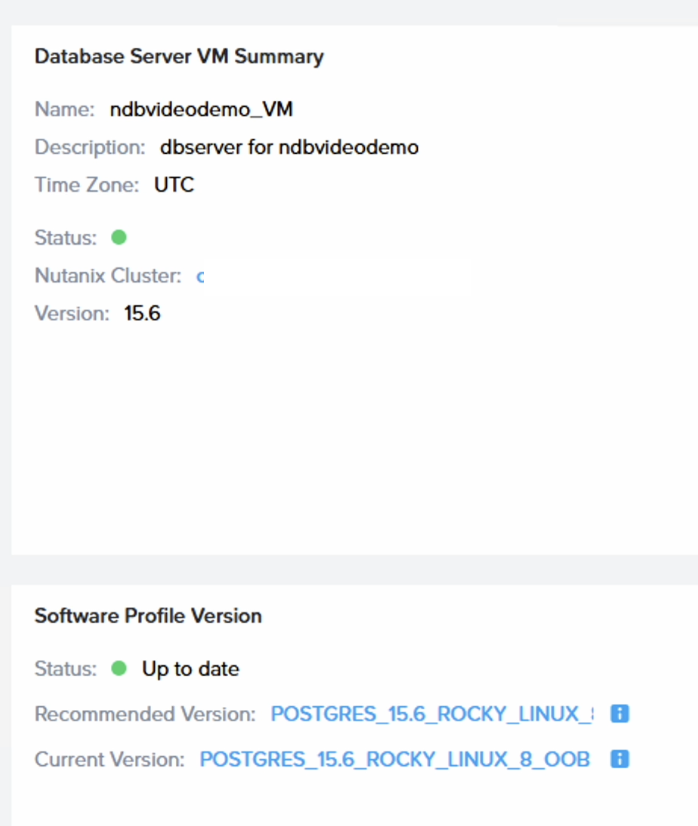
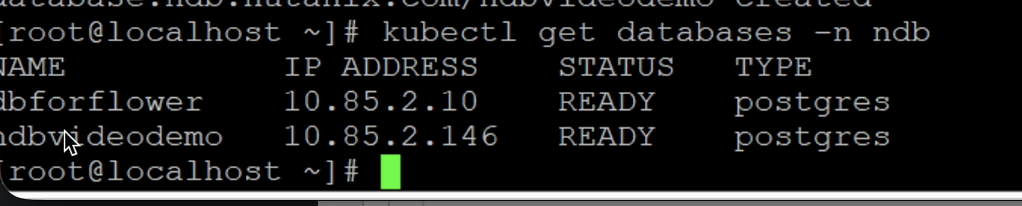
Je peux aussi lister mes ressources de type database dans NKP/K8s de la manière suivante :
kubectl get databases -n ndb
Utilisation
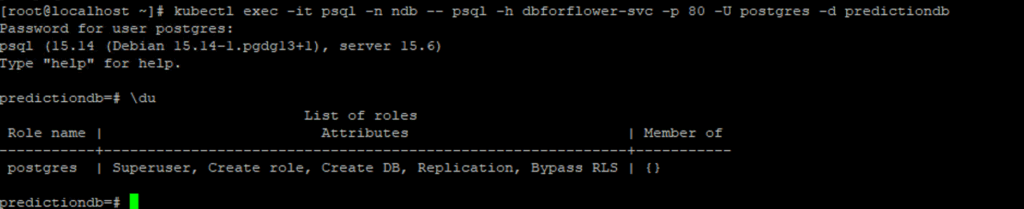
Dans K8s depuis n’importe quel pod disposant d’un client psql, je peux venir consommer, interroger ma base de donnée.