

L’objectif de cet article est d’illustrer une fonction permettant l’intégration du produit Nutanix DataBase dans Self-Service.
J’ai toujours apprécié intégrer et faire cohabiter ensemble les différents produits du portfolio Nutanix pour optimiser leur utilisation quotidienne.
Self-Service, le produit de gestion et d’automatisation du cycle de vie des applications n’est plus à présenter. Il comporte un grand nombre d’outils intéressants. Nous allons ici voir un aperçu de la gestion d’une base de données postgreSQL dans NDB via un Runbook Self-Service.
Cette intégration va permettre d’agir sur une instance existante ou sur la création d’une nouvelle instance avec les types d’opérations suivantes :
- Créer un clone à partir d’une Time Machine
- Créer un snapshot
- Créer une database sur un nouveau serveur de base de données
- Restaurer à partir d’une Time Machine une base de données existante
- Supprimer une bade de données et la Time Machine associée
Cette fonctionnalité permet d’interagir pour le moment uniquement avec des serveurs et bases de données Postgres mais on peut espérer la voir s’étendre à plusieurs autres technologies prochainement. Pour en savoir plus dans la documentation officielle c’est ici : Nutanix Database Service Integration with Self-Service
Voici en détail l’implémentation de cette fonctionnalité intéressante pouvant couvrir plusieurs cas d’usage à automatiser (clone de bases pour des tests d’intégrations, rafraichissement de données …)
Ajout de NDB dans le projet Self-Service
La première étape est d’ajouter NDB comme un Service Nutanix dans les Account du projet dans Self-Service.
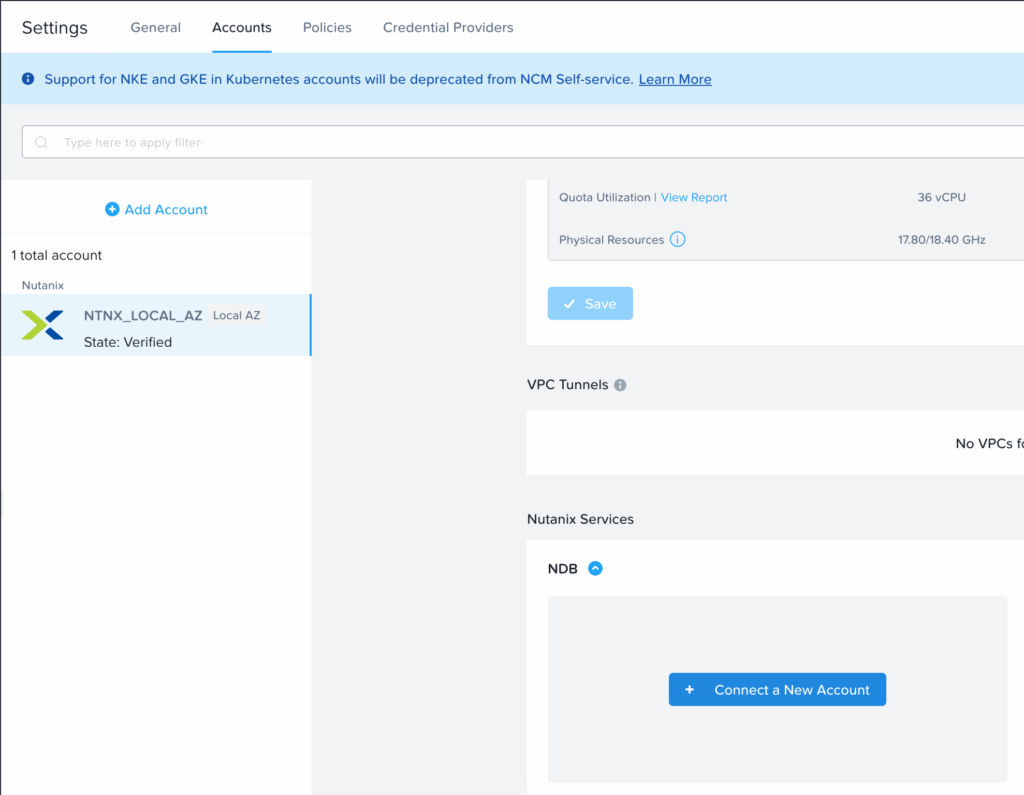
Il suffit ensuite de renseigner les informations nécessaires : utilisateur, mot de passe, IP et nom. (Pour le compte, j’ai dédié un compte de service svc-calm dans NDB).
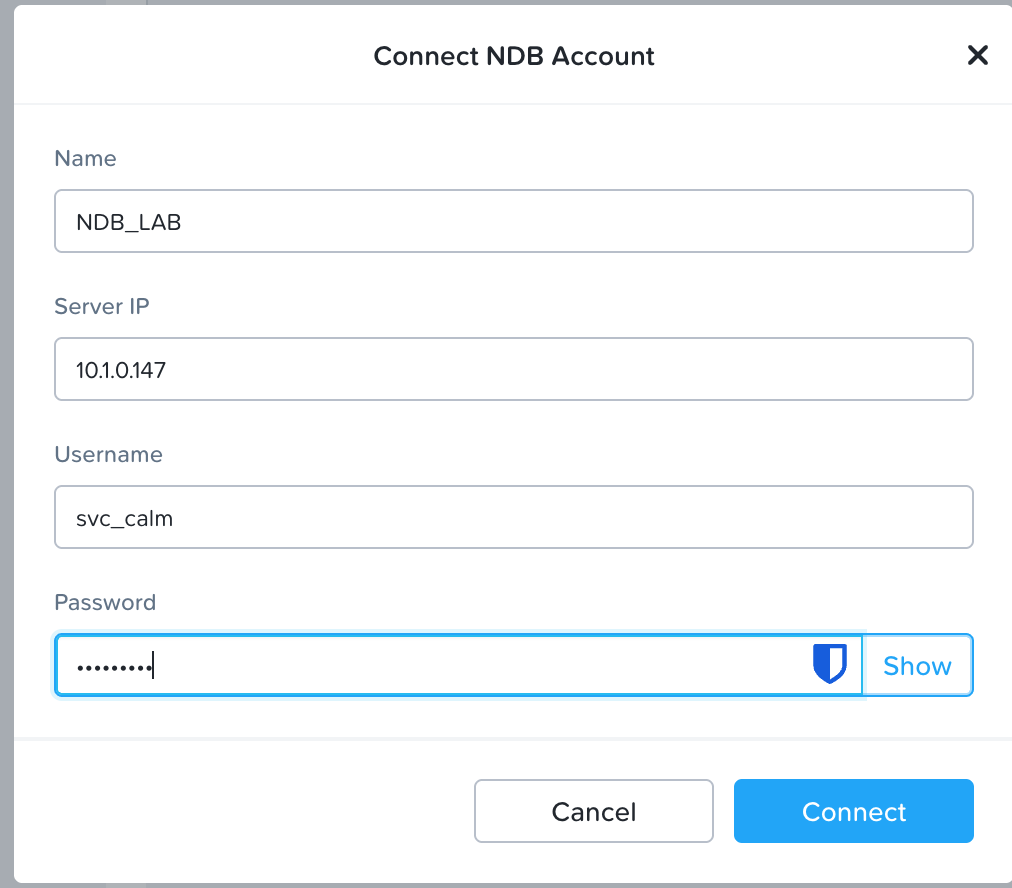
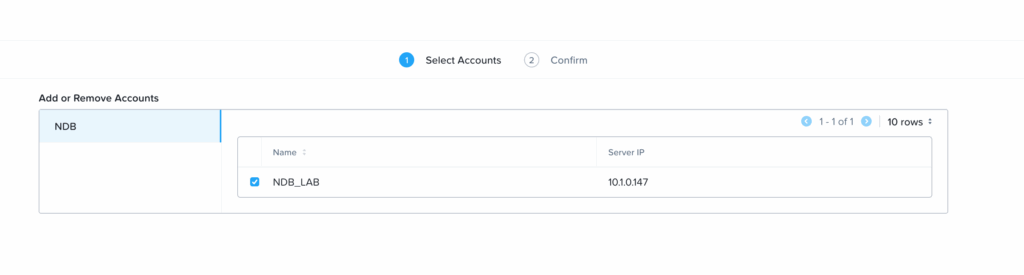
Il suffit ensuite de renseigner les informations nécessaires : utilisateur, mot de passe, IP et nom. (Pour le compte, j’ai dédié un compte de service svc-calm dans NDB).
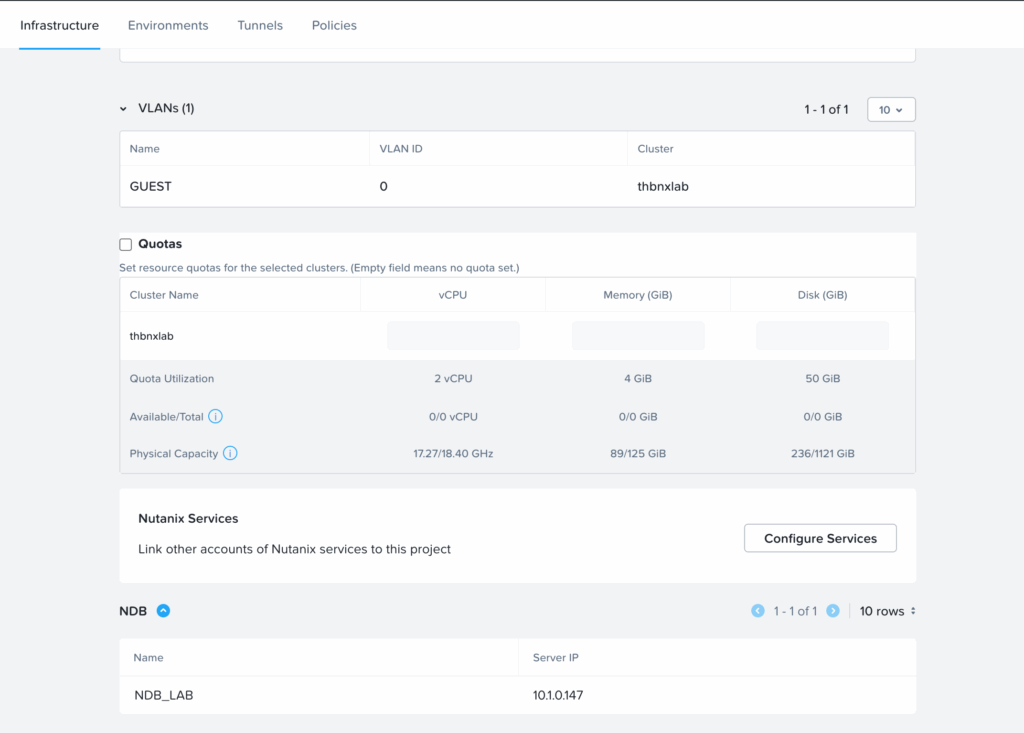
Utilisation dans un Runbook
Je peux ensuite créé un nouveau Runbook ou aller dans un Runbook existant.
L’intégration NDB repose ensuite sur la création du type de tâche. Dans mon Runbook, je vais pouvoir créer une nouvelle tâche de type « Database Operation ».
J’ai ensuite la possibilité de choisir le type d’opération a exécuter : Ici par exemple je vais prendre un snapshot d’une DB existante avec un Time machine en cours.
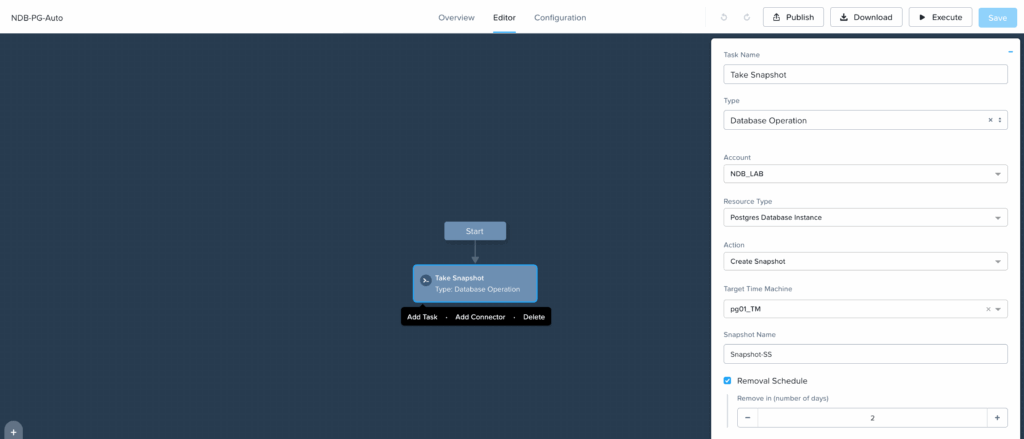
Je lui indique les paramètres : Time Machine, Nom du snapshot et politique de retention.
Le petit point manquant pour l’instant, c’est qu’il n’est pas possible d’utiliser une macro pour le nom du snapshot avec la date par exemple.
A noter que différents paramètres sont récupérables sous forme de variables tel que le snapshot uuid pour être réutilisé dans des tâches suivantes.
Exécution du Runbook et vérification
On peut ensuite lancer le runbook et vérifier son exécution coté NDB.
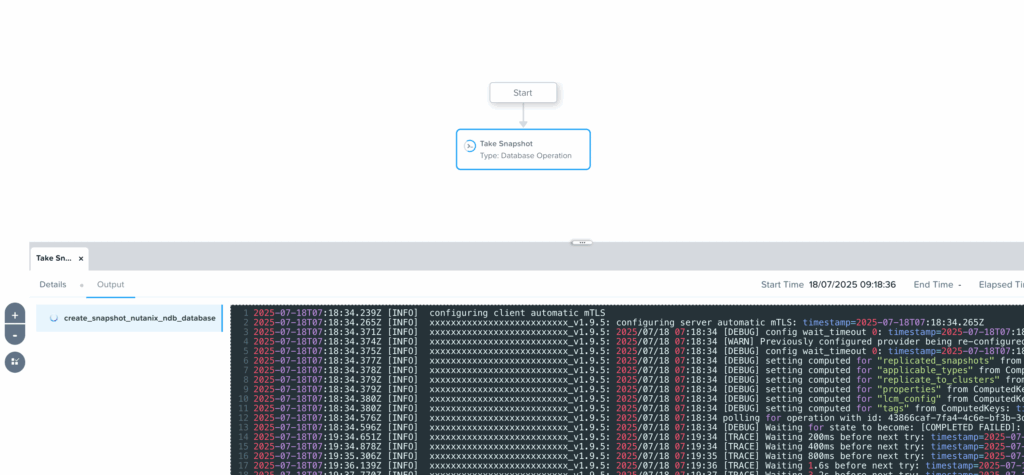
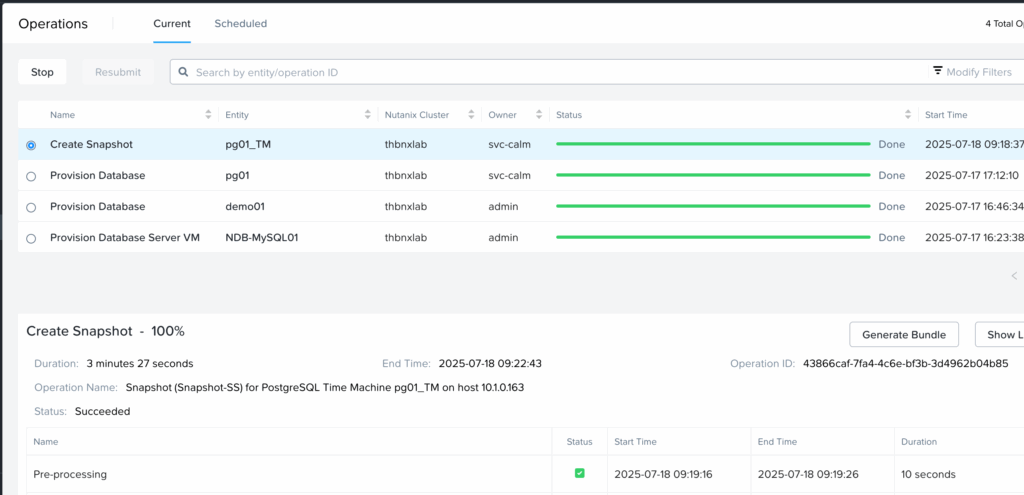
Le Runbook s’exécute correctement et le snapshot est bien créé coté NDB dans la liste des tâches.
Extensions et étapes supplémentaires possibles
Plusieurs choses sont automatisables et optimisables pour faire de ce scénario un vrai cas d’usage.
Par exemple je peux créer un scheduler via le policy engine pour automatiser cette tâche de manière régulière.
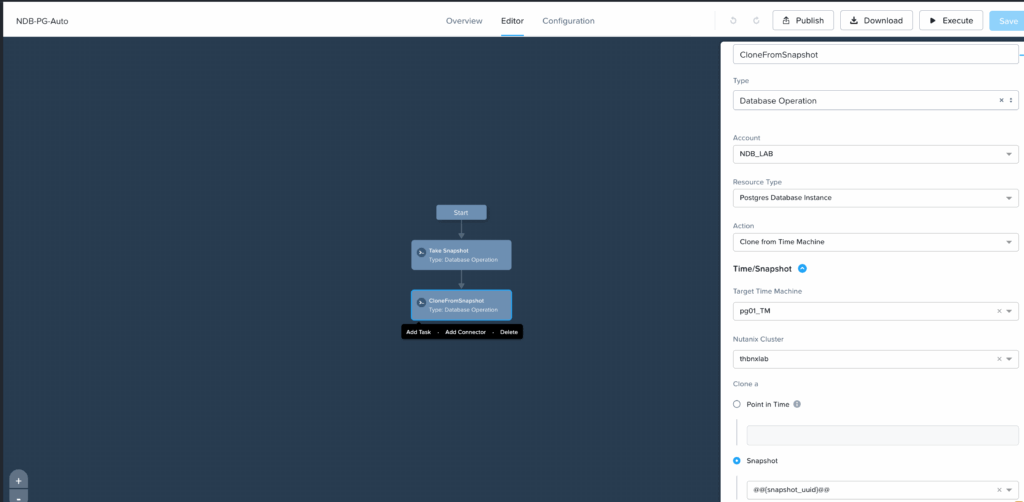
Je peux aussi compléter ce workflow avec l’ajout d’une tâche supplémentaire au scénario précédent qui vient faire un clone de la DB à partir du snapshot pris précédemment comme ci dessous avec la reprise en macro de l’UUID du snapshot précédent.

Merci Theo pour cette illustration des services additionnels qu’offrent un Cluster Nutanix et de l’intégration qu’il existe entre ces différents services.
Preuve est ainsi faite de l’avantage et de la simplicité de la mise en place de cette intégration.